
Яндекс диктор
Затраты на собственную разработку «Яндекс» не раскрывает. Представители компании утверждают, что создали продукт своими силами – без привлечения сторонних специалистов.
Подобные технологии есть и у других интернет-компаний: у Apple есть несколько приложений (разработчик – Nuance). Например, программа Dragon Dictation распознает текст и позволяет скопировать и вставить его в другое приложение, а также сразу отослать в электронном письме или SMS, отправить в Twitter или Facebook, а Dragon Search – это голосовой поиск. Dragon Dictation и Dragon Search используют облачные технологии, а база голосовых данных для распознавания речи находится на серверах Nuance, пишет Apple Insider, поэтому их работа зависит от скорости интернета.
В устройствах с операционной системой Android (разработчик – Google) есть голосовой поиск, возможность перевода речи в текст. С 2013 года функция распознавания речи появилась и в браузере Google Chrome: система умеет переводить устную речь в печатный текст. Разработчики благодаря Web Speech API могут встраивать функции, связанные с распознаванием речи и выполнением голосовых команд, в свои приложения.
Технологии обеих компаний умеют распознавать русский язык.
Руководитель отдела голосовых технологий и продуктов «Яндекса» уверяет, что Yandex SpeechKit, в отличие от зарубежных конкурентов, лучше распознает русский язык. Он добавил, что Google дает возможность сторонним разработчикам использовать технологию только в оперативной системе Android, а технологии «Яндекса» доступны на разных операционных системах и других объектах, например, их возможно встроить в автомобиль или кофеварку. Также у Google нет голосовой активации и выделения смысловых объектов, говорит Филиппов.
Свою технологию распознавания речи Yandex SpeechKit российская компания представила в прошлом году. Она основана на исследовании больших массивов данных, обучении нейронных сетей и вычислительных мощностях «Яндекса», поясняют разработчики. Они уверяют, что система верно распознает 88% слов по коротким запросам, 95% слов – по геозапросам.
Сторонние разработчики получают технологии «Яндекса», подписавшись на библиотеку Yandex SpeechKit Mobile SDK: она позволяет встраивать речевые технологии в приложения для Android, iOS и Windows Phone. «Яндекс» гарантирует работу только тех приложений, которым нужно до 10 тыс. головых запросов в сутки. Все данные компания обрабатывает на своих серверах.
Yandex SpeechKit работает примерно в 500 мобильных приложениях, в том числе самой компании («Яндекс.Навигатор», «Яндекс.Браузер», «Яндекс.Город», «Яндекс.Карты» и «Яндекс.Поиск»). Услуга заинтересовала разработчиков из разных сфер, утверждают в пресс-службе. «Это приложения совершенно различных тематик: от игр до специализированных корпоративных приложений», – сказала РБК представитель компании Юлия Бабикова.
Кроме мобильного сервиса, в августе 2014 года «Яндекс» запустил облачный. SpeechKit Cloud позволяет добавить функцию распознавания речи в разные программы и устройства – от компьютерной игры до робота. Эта технология, уверяют в компании, уже используется в колл-центрах для автоматизации обращений, с большим количеством партнеров из разных сфер ведутся переговоры.
SpeechKit Cloud доступен на коммерческой основе. «Мы выдали 600 ключей компаниям из разных сфер (робототехника, телефония, медицина и других), которые вот прямо сейчас тестируют технологию распознавания речи Yandex SpeechKit в своих продуктах и сервисах», – пояснили РБК в пресс-службе «Яндекса».
 На Yet another Conference 2013 мы представили разработчикам нашу новую библиотеку Yandex SpeechKit. Это публичный API для распознавания речи, который могут использовать разработчики под Android и iOS. Скачать SpeechKit, а также ознакомиться с документацией, можно .
На Yet another Conference 2013 мы представили разработчикам нашу новую библиотеку Yandex SpeechKit. Это публичный API для распознавания речи, который могут использовать разработчики под Android и iOS. Скачать SpeechKit, а также ознакомиться с документацией, можно .
Yandex SpeechKit позволяет напрямую обращаться к тому бэкэнду, который успешно применяется в мобильных приложениях Яндекса. Мы достаточно долго развивали эту систему и сейчас правильно распознаем 94% слов в Навигаторе и Мобильных Картах, а также 84% слов в Мобильном Браузере. При этом на распознавание уходит чуть больше секунды. Это уже весьма достойное качество, и мы активно работаем над его улучшением.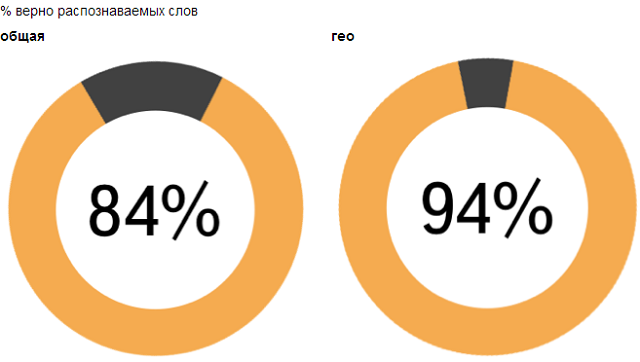
Можно утверждать, что уже в скором времени голосовые интерфейсы практически не будут отличаться по надежности от классических способов ввода. Подробный рассказ о том, как нам удалось добиться таких результатов, и как устроена наша система, под катом.
Распознавание речи — одна из самых интересных и сложных задач искусственного интеллекта. Здесь задействованы достижения весьма различных областей: от компьютерной лингвистики до цифровой обработки сигналов. Чтобы понять, как должна быть устроена машина, понимающая речь, давайте для начала разберемся, с чем мы имеем дело.
I. Основы
Звучащая речь для нас — это, прежде всего, цифровой сигнал. И если мы посмотрим на запись этого сигнала, то не увидим там ни слов, ни четко выраженных фонем — разные «речевые события» плавно перетекают друг в друга, не образуя четких границ. Одна и та же фраза, произнесенная разными людьми или в различной обстановке, на уровне сигнала будет выглядеть по-разному. Вместе с тем, люди как-то распознают речь друг друга: следовательно, существуют инварианты, согласно которым по сигналу можно восстановить, что же, собственно, было сказано. Поиск таких инвариантов — задача акустического моделирования.
Предположим, что речь человека состоит из фонем (это грубое упрощение, но в первом приближении оно верно). Определим фонему как минимальную смыслоразличительную единицу языка, то есть звук, замена которого может привести к изменению смысла слова или фразы. Возьмем небольшой участок сигнала, скажем, 25 миллисекунд. Назовем этот участок «фреймом». Какая фонема была произнесена на этом фрейме? На этот вопрос сложно ответить однозначно — многие фонемы чрезвычайно похожи друг на друга. Но если нельзя дать однозначный ответ, то можно рассуждать в терминах «вероятностей»: для данного сигнала одни фонемы более вероятны, другие менее, третьи вообще можно исключить из рассмотрения. Собственно, акустическая модель — это функция, принимающая на вход небольшой участок акустического сигнала (фрейм) и выдающая распределение вероятностей различных фонем на этом фрейме. Таким образом, акустическая модель дает нам возможность по звуку восстановить, что было произнесено — с той или иной степенью уверенности.
Еще один важный аспект акустики — вероятность перехода между различными фонемами. Из опыта мы знаем, что одни сочетания фонем произносятся легко и встречаются часто, другие сложнее для произношения и на практике используются реже. Мы можем обобщить эту информацию и учитывать ее при оценке «правдоподобности» той или иной последовательности фонем.
Теперь у нас есть все инструменты, чтобы сконструировать одну из главных «рабочих лошадок» автоматического распознавания речи — скрытую марковскую модель (HMM, Hidden Markov Model). Для этого на время представим, что мы решаем не задачу распознавания речи, а прямо противоположную — преобразование текста в речь. Допустим, мы хотим получить произношение слова «Яндекс». Пусть слово «Яндекс» состоит из набора фонем, скажем, . Построим конечный автомат для слова «Яндекс», в котором каждая фонема представлена отдельным состоянием. В каждый момент времени находимся в одном из этих состояний и «произносим» характерный для этой фонемы звук (как произносится каждая из фонем, мы знаем благодаря акустической модели). Но одни фонемы длятся долго (как в слове «Яндекс»), другие практически проглатываются. Здесь нам и пригодится информация о вероятности перехода между фонемами. Сгенерировав звук, соответствующий текущему состоянию, мы принимаем вероятностное решение: оставаться нам в этом же состоянии или же переходить к следующему (и, соответственно, следующей фонеме).
Более формально HMM можно представить следующим образом. Во-первых, введем понятие эмиссии. Как мы помним из предыдущего примера, каждое из состояний HMM «порождает» звук, характерный именно для этого состояния (т.е. фонемы). На каждом фрейме звук «разыгрывается» из распределения вероятностей, соответствующего данной фонеме. Во-вторых, между состояниями возможны переходы, также подчиняющиеся заранее заданным вероятностным закономерностям. К примеру, вероятность того, что фонема будет «тянуться», высока, чего нельзя сказать о фонеме . Матрица эмиссий и матрица переходов однозначно задают скрытую марковскую модель.
Хорошо, мы рассмотрели, как скрытая марковская модель может использоваться для порождения речи, но как применить ее к обратной задаче — распознаванию речи? На помощь приходит алгоритм Витерби. У нас есть набор наблюдаемых величин (собственно, звук) и вероятностная модель, соотносящая скрытые состояния (фонемы) и наблюдаемые величины. Алгоритм Витерби позволяет восстановить наиболее вероятную последовательность скрытых состояний.
Пусть в нашем словаре распознавания всего два слова: «Да» () и «Нет» (). Таким образом, у нас есть две скрытые марковские модели. Далее, пусть у нас есть запись голоса пользователя, который говорит «да» или «нет». Алгоритм Витерби позволит нам получить ответ на вопрос, какая из гипотез распознавания более вероятна.
Теперь наша задача сводится к тому, чтобы восстановить наиболее вероятную последовательность состояний скрытой марковской модели, которая «породила» (точнее, могла бы породить) предъявленную нам аудиозапись. Если пользователь говорит «да», то соответствующая последовательность состояний на 10 фреймах может быть, например, или . Аналогично, возможны различные варианты произношения для «нет» — например, и . Теперь найдем «лучший», то есть наиболее вероятный, способ произнесения каждого слова. На каждом фрейме мы будем спрашивать нашу акустическую модель, насколько вероятно, что здесь звучит конкретная фонема (например, и ); кроме того, мы будем учитывать вероятности переходов (->, ->, ->). Так мы получим наиболее вероятный способ произнесения каждого из слов-гипотез; более того, для каждого из них мы получим меру, насколько вообще вероятно, что произносилось именно это слово (можно рассматривать эту меру как длину кратчайшего пути через соответствующий граф). «Выигравшая» (то есть более вероятная) гипотеза будет возвращена как результат распознавания.
Алгоритм Витерби достаточно прост в реализации (используется динамическое программирование) и работает за время, пропорциональное произведению количества состояний HMM на число фреймов. Однако не всегда нам достаточно знать самый вероятный путь; например, при тренировке акустической модели нужна оценка вероятности каждого состояния на каждом фрейме. Для этого используется алгоритм Forward-Backward.
Однако акустическая модель — это всего лишь одна из составляющих системы. Что делать, если словарь распознавания состоит не из двух слов, как в рассмотренном выше примере, а из сотен тысяч или даже миллионов? Многие из них будут очень похожи по произношению или даже совпадать. Вместе с тем, при наличии контекста роль акустики падает: невнятно произнесенные, зашумленные или неоднозначные слова можно восстановить «по смыслу». Для учета контекста опять-таки используются вероятностные модели. К примеру, носителю русского языка понятно, что естественность (в нашем случае — вероятность) предложения «мама мыла раму» выше, чем «мама мыла циклотрон» или «мама мыла рама». То есть наличие фиксированного контекста «мама мыла …» задает распределение вероятностей для следующего слова, которое отражает как семантику, так и морфологию. Такой тип языковых моделей называется n-gram language models (триграммы в рассмотренном выше примере); разумеется, существуют куда более сложные и мощные способы моделирования языка.
II. Что под капотом у Yandex ASR?
Теперь, когда мы представляем себе общее устройство систем распознавания речи, опишем более подробно детали технологии Яндекса — лучшей, согласно нашим данным, системы распознавания русской речи.
При рассмотрении игрушечных примеров выше мы намеренно сделали несколько упрощений и опустили ряд важных деталей. В частности, мы утверждали, что основной «строительной единицей» речи является фонема. На самом деле фонема — слишком крупная единица; чтобы адекватно смоделировать произношение одиночной фонемы, используется три отдельных состояния — начало, середина и конец фонемы. Вместе они образуют такую же HMM, как представлена выше. Кроме того, фонемы являются позиционно-зависимыми и контекстно-зависимыми: формально «одна и та же» фонема звучит существенно по-разному в зависимости от того, в какой части слова она находится и с какими фонемами соседствует. Вместе с тем, простое перечисление всех возможных вариантов контекстно-зависимых фонем вернет очень большое число сочетаний, многие из которых никогда не встречаются в реальной жизни; чтобы сделать количество рассматриваемых акустических событий разумным, близкие контекстно-зависимые фонемы объединяются на ранних этапах тренировки и рассматриваются вместе.
Таким образом, мы, во-первых, сделали фонемы контекстно-зависимыми, а во-вторых, разбили каждую из них на три части. Эти объекты — «части фонем» — теперь составляют наш фонетический алфавит. Их также называют сенонами. Каждое состояние нашей HMM — это сенон. В нашей модели используется 48 фонем и около 4000 сенонов.
Итак, наша акустическая модель все так же принимает на вход звук, а на выходе дает распределение вероятностей по сенонам. Теперь рассмотрим, что конкретно подается на вход. Как мы говорили, звук нарезается участками по 25 мс («фреймами»). Как правило, шаг нарезки составляет 10 мс, так что соседние фреймы частично пересекаются. Понятно, что «сырой» звук — амплитуда колебаний по времени — не самая информативная форма представления акустического сигнала. Спектр этого сигнала — уже гораздо лучше. На практике обычно используется логарифмированный и отмасштабированный спектр, что соответствует закономерностям человеческого слухового восприятия (Mel-преобразование). Полученные величины подвергаются дискретному косинусному преобразованию (DCT), и в результате получается MFCC — Mel Frequency Cepstral Coefficients. (Слово Cepstral получено перестановкой букв в Spectral, что отражает наличие дополнительного DCT). MFCC — это вектор из 13 (обычно) вещественных чисел. Они могут использоваться как вход акустической модели «в сыром виде», но чаще подвергаются множеству дополнительных преобразований.
Тренировка акустической модели — сложный и многоэтапный процесс. Для тренировки используются алгоритмы семейства Expectation-Maximization, такие, как алгоритм Баума-Велша. Суть алгоритмов такого рода — в чередовании двух шагов: на шаге Expectation имеющаяся модель используется для вычисления матожидания функции правдоподобия, на шаге Maximization параметры модели изменяются таким образом, чтобы максимизировать эту оценку. На ранних этапах тренировки используются простые акустические модели: на вход даются простые MFCC features, фонемы рассматриваются вне контекстной зависимости, для моделирования вероятности эмиссии в HMM используется смесь гауссиан с диагональными матрицами ковариаций (Diagonal GMMs — Gaussian Mixture Models). Результаты каждой предыдущей акустической модели являются стартовой точкой для тренировки более сложной модели, с более сложным входом, выходом или функцией распределения вероятности эмиссии. Существует множество способов улучшения акустической модели, однако наиболее значительный эффект имеет переход от GMM-модели к DNN (Deep Neural Network), что повышает качество распознавания практически в два раза. Нейронные сети лишены многих ограничений, характерных для гауссовых смесей, и обладают лучшей обобщающей способностью. Кроме того, акустические модели на нейронных сетях более устойчивы к шуму и обладают лучшим быстродействием.
Нейронная сеть для акустического моделирования тренируется в несколько этапов. Для инициализации нейросети используется стек из ограниченных машин Больцмана (Restricted Boltzmann Machines, RBM). RBM — это стохастическая нейросеть, которая тренируется без учителя. Хотя выученные ей веса нельзя напрямую использовать для различения между классами акустических событий, они детально отражают структуру речи. Можно относиться к RBM как к механизму извлечения признаков (feature extractor) — полученная генеративная модель оказывается отличной стартовой точкой для построения дискриминативной модели. Дискриминативная модель тренируется с использованием классического алгоритма обратного распространения ошибки, при этом применяется ряд технических приемов, улучшающих сходимость и предотвращающих переобучение (overfitting). В итоге на входе нейросети — несколько фреймов MFCC-features (центральный фрейм подлежит классификации, остальные образуют контекст), на выходе — около 4000 нейронов, соответствующих различным сенонам. Эта нейросеть используется как акустическая модель в production-системе.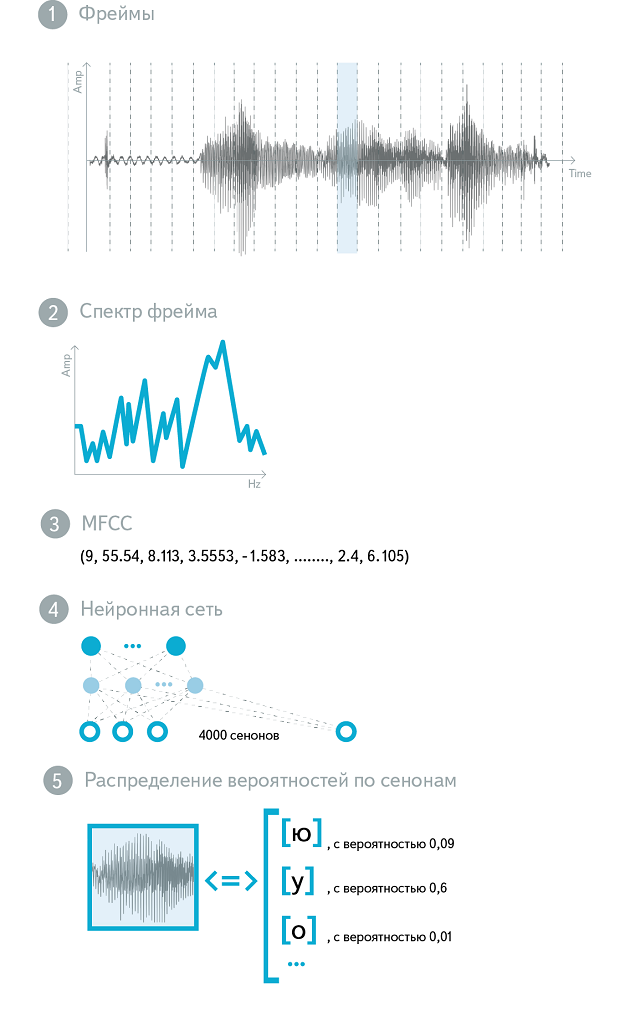
Рассмотрим подробнее процесс декодирования. Для задачи распознавания спонтанной речи с большим словарем подход, описанный в первой секции, неприменим. Необходима структура данных, соединяющая воедино все возможные предложения, которые может распознать система. Подходящей структурой является weighted finite-state transducer (WFST) — по сути, просто конечный автомат с выходной лентой и весами на ребрах. На входе этого автомата — сеноны, на выходе — слова. Процесс декодирования сводится к тому, чтобы выбрать лучший путь в этом автомате и предоставить выходную последовательность слов, соответствующую этому пути. При этом цена прохода по каждой дуге складывается из двух компонент. Первая компонента известна заранее и вычисляется на этапе сборки автомата. Она включает в себя стоимость произношения, перехода в данное состояние, оценку правдоподобия со стороны языковой модели. Вторая компонента вычисляется отдельно для конкретного фрейма: это акустический вес сенона, соответствующего входному символу рассматриваемой дуги. Декодирование происходит в реальном времени, поэтому исследуются не все возможные пути: специальные эвристики ограничивают набор гипотез наиболее вероятными.
Разумеется, наиболее интересная с технической точки зрения часть — это построение такого автомата. Эта задача решается в оффлайне. Чтобы перейти от простых HMM для каждой контекстно-зависимой фонемы к линейным автоматам для каждого слова, нам необходимо использовать словарь произношений. Создание такого словаря невозможно вручную, и здесь используются методы машинного обучения (а сама задача в научном сообществе называется Grapheme-To-Phoneme, или G2P). В свою очередь, слова «состыковываются» друг с другом в языковую модель, также представленную в виде конечного автомата. Центральной операцией здесь является композиция WFST, но также важны и различные методы оптимизации WFST по размеру и эффективности укладки в памяти.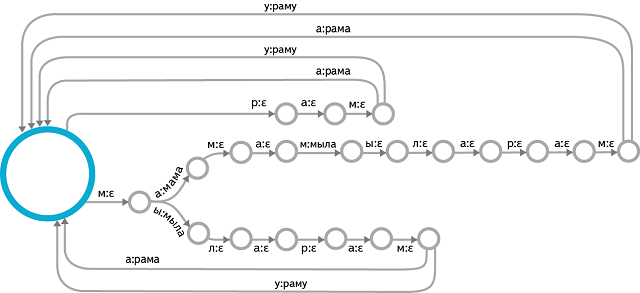
Результат процесса декодирования — список гипотез, который может быть подвергнут дальнейшей обработке. К примеру, можно использовать более мощную языковую модель для переранжирования наиболее вероятных гипотез. Результирующий список возвращается пользователю, отсортированный по значению confidence — степени нашей уверенности в том, что распознавание прошло правильно. Нередко остается всего одна гипотеза, в этом случае приложение-клиент сразу переходит к выполнению голосовой команды.
В заключение коснемся вопроса о метриках качества систем распознавания речи. Наиболее популярна метрика Word Error Rate (и обратная ей Word Accuracy). По существу, она отражает долю неправильно распознанных слов. Чтобы рассчитать Word Error Rate для системы распознавания речи, используют размеченные вручную корпуса голосовых запросов, соответствующих тематике приложения, использующего распознавание речи.
Литература по теме:
1. Mohri, M., Pereira, F., & Riley, M. (2008). Speech recognition with weighted finite-state transducers. In Springer Handbook of Speech Processing (pp. 559-584). Springer Berlin Heidelberg.
Рекомендуем почитать:
Xakep #257. Pivoting
- Подписка на «Хакер»
Компания «Яндекс» в рамках конференции YaC 2014 представила приложение «Яндекс.Диктовка», призванное минимизировать необходимость набирать текст на сенсорной клавиатуре твоего гаджета.
Принцип работы программы основан на технологии SpeechKit, которая неплохо себя зарекомендовала в некоторых других продуктах компании. Для того чтобы активировать «Яндекс.Диктовку», достаточно произнести фразу «Яндекс, записывай». После этого программа начнёт слушать то, что ты говоришь, и сразу же преобразовывать фразы в текст. Приложение умеет самостоятельно расставлять знаки препинания, ориентируясь на паузы в речи.
Интересной особенностью «Яндекс.Диктовки» является поддержка множества голосовых команд. При этом они необязательно должны быть шаблонными. Например, ты можешь попросить удалить последнее слово, выделить весь абзац, начать с новой строки или даже поставить смайлик — приложение выполнит твоё пожелание.
Закончив написание заметки, командой «Прочитай всё» попроси «Яндекс.Диктовку» озвучить её, а также опубликовать текст в социальных сетях, сохранить в качестве заметки, отправить в виде электронного письма или сообщения.
Приложение доступно уже сейчас совершенно бесплатно в Yandex.Store. Вскоре «Яндекс.Диктовка» появится также в App Store и Google Play.
Компания Яндекс выпустила экспериментальное приложение под названием Яндекс.Диктовка, созданное на базе речевых технологий Yandex SpeechKit.
Как сообщают разработчики, приложение Яндекс.Диктовка предназначено для набора текста голосом. Чтобы начать набор, достаточно произнести фразу «Яндекс, записывай». Приложение начнет слушать пользователя и преобразовывать его речь в текст в режиме реального времени.
Редактировать текст тоже можно голосом. Вы можете сказать, например, «Удали последнее слово», «Начни с новой строки», «Выдели весь текст», «Добавь веселый смайлик» — и Яндекс.Диктовка выполнит ваше пожелание. По команде «Прочитай всё» приложение озвучит текст, который вы надиктовали. Готовый текст можно сохранить как заметку, отправить в виде письма или СМС. Все это тоже можно сделать голосом.
Приложение Яндекс.Диктовка уже доступно в магазине приложений Яндекса и, по словам разработчиков, позже оно появится в магазинах Google Play и App Store.
Как поясняют разработчики, приложение Яндекс.Диктовка выпущено для того, чтобы показать новые возможности Yandex SpeechKit — разработанной Яндексом собственной системы распознавания речи. Она используется как в сервисах Яндекса — например, в Яндекс.Навигаторе, — так и в продуктах сторонних разработчиков.
Сегодня SpeechKit был дополнен тремя новыми технологиями, которые делают общение человека с компьютером более полноценным. Теперь система умеет включаться по голосовой команде, понимает смысл слов, а также не только слушает пользователя, но и отвечает ему — с помощью технологии синтеза речи.
Cтандартные библиотеки распознавания речи и озвучки текста в iOS дают массу возможностей. Из доклада VolkovRoman вы узнаете, как за счёт минимального количества кода научить ваше приложение проговаривать текст и кастомизировать озвучку. Рома рассмотрел API распознавания речи, его ограничения и особенности, lifecycle запроса на распознавание и методы работы в офлайн-режиме. Вас ждут примеры UX, обход существующих багов и особенности работы с аудиосессией.
— Всем привет, меня зовут Роман Волков. Сегодня мы поговорим о том, как научить ваше мобильное приложение общаться с вашими пользователями.
Прежде чем мы начнем, коротко обо мне. До iOS-разработки я занимался разработкой интеграционных систем в банковской сфере и разработкой аналитических систем в нефтяной сфере. Я не понаслышке знаю, что такое стандарт PCI DSS и, например, как инженеры понимают, что происходит в скважине во время бурения, только лишь на основе температурных данных.
С 2016 года я занимаюсь iOS-разработкой. У меня есть опыт как фриланса, так и удаленки, опыт участия в запуске нескольких стартапов. В том числе я делал брендовое приложение для компании Rolls Royce.
В 2018 году я присоединился к команде Prisma, развивал приложение Prisma и участвовал в разработке и запуске фоторедактора Lensa. С 2019 года я перешел в Яндекс в качестве iOS-разработчика. С 2020 года я руковожу группой мобильной разработки Яндекс.Переводчика. Приложение Переводчик перестало быть просто приложением для работы с текстом. У нас есть много классных фич, таких как перевод по фото, диалоговый режим, ввод голосом, озвучка и многое другое.
Только начав погружаться в тему работы со звуком в iOS, я не нашел какого-то компактного материала, который включал бы в себя и работу с аудиосессией, и с синтезом, и с распознаванием речи. Именно поэтому я решил сделать этот доклад.
Он будет состоять из четырех частей. Сначала мы поговорим о том, что такое аудиосессия, как с ней правильно работать, как она влияет на работу вашего приложения. Далее перейдем к синтезу речи. Рассмотрим, как можно в несколько строк кода озвучить людей текст прямо на телефоне. Далее мы переключимся на распознавание речи. И в заключение посмотрим, как все эти возможности можно предоставить пользователю в офлайн-режиме и какие у этого особенности.
Вариантов использования озвучки и распознавания речи довольно-таки много. Мое самое любимое — конвертация чужих аудиосообщений в текст. И меня радует, что, например, команда Яндекс.Мессенджера как раз таки сделала такую фичу. Надеюсь, другие мессенджеры подтянутся и сделают это у себя тоже.
Мы плавно переходим к первой части доклада, это AVAudioSession.
Аудиосессия — прослойка между нашим приложением и операционной системой. Точнее — между вашим приложением и железом для работы со звуком: динамиком и микрофоном. В iOS, watchOS и tvOS каждое приложение имеет преднастроенную аудиосессию по умолчанию. Эта преднастройка варьируется от одной ОС к другой.
Если говорить именно про iOS, аудиосессия по умолчанию поддерживает воспроизведение звука, но запрещает любую запись. Если переключатель беззвучного режима выставлен в режим «без звука», то глушатся абсолютно все звуки внутри вашего приложения. И третье: блокировка устройства останавливает проигрывание всех звуков внутри вашего приложения.
Настройка аудиосессии состоит из трех пунктов: это выбор категории, режима и дополнительных опций. Мы рассмотрим каждый из пунктов по отдельности.
Начнем с категории. Категория — это некий набор настроек базового поведения аудиосессии. Категория представляет из себя набор параметров, которые позволяют операционной системе максимально соответствовать, скажем так, названию этой категории. Поэтому Apple рекомендует выбирать для своего приложения категорию, максимально приближенную из доступных. На данный момент в iOS 13 доступно шесть категорий. Есть еще седьмая категория, но она помечена как deprecated, ее не стоит использовать.
В докладе мы рассмотрим три категории: playback, record и playAndRecord. Режим позволяет дополнять возможности установленной категории, так как некоторые режимы доступны только для определенных категорий.
Например, на слайде вы видите режим moviePlayback, и его можно установить только для категории Playback.
Установка режима moviePlayback позволяет аудиосессии автоматически улучшать качество проигрываемого звука для встроенных динамиков и для наушников. В докладе мы будем использовать только режим «по умолчанию». Но я хочу отметить, что если вы будете использовать несовместимую пару категории и режима, то будет использован дефолтный Mode.
Третье — options, точечные настройки работы аудиосессии. Например, можно настроить то, как звук с вашего приложения будет миксоваться со звуком из других приложений, настроить правильную деактивацию аудиосессии так, чтобы другие приложения могли узнать, что ваше приложение закончило работу со звуком.
Сначала мы рассмотрим установку категории для проигрывания, а именно playback. Это одна из категорий, предназначенных только для проигрывания звука. Если она установлена, то активация аудиосессии прерывает другие проигрываемые аудио, например, из других приложений.
Важно еще и то, что аудио будет проигрываться, даже если переключатель беззвучного режима переведен в беззвучный режим.
Также для этой категории доступна опция проигрывания в бэкграунд-состоянии, но для этого у вашего приложения должен быть включен Audio, AirPlay, and Picture in Picture.
Рассмотрим две опции, которые видны на слайде. Первая — mixWithOthers. Если вы активируете аудиосессию с данной опцией, то проигрывание звука внутри вашего приложения будет смиксовано с текущим проигрываемым звуком, например с музыкой, с одним уровнем громкости. Но если вы хотите, чтобы ваш звук превалировал в плане громкости над текущим проигрыванием, вы можете использовать опцию duckOthers. Она понижает громкость звука, который проигрывается в бэкграунде, и возвращает обратно, когда проигрывание звука внутри вашего приложения закончилось.
Например, такое можно наблюдать в навигационных приложениях: для анонса маршрута то, что вы слушаете сейчас, приглушается, проигрывается анонс, и затем все возвращается в первоначальное состояние.
Рассмотрим вариант настройки аудиосессии для распознавания с микрофона. Категория Record заглушает все проигрываемые аудио, пока аудиосессия с этой категорией активна в приложении. Record не может заглушить системные звуки, такие как звонки, будильники — в общем, стандартные звуки, которые имеют более высокий приоритет.
Также вы можете добавить опцию allowBluetoothA2DP, это позволяет использовать гарнитуры типа AirPods для записи звука с микрофона и для проигрывания звука в них. Для этого существует более старая опция, которая звучит просто как allowBluetooth, но с ее использованием сильно падает качество звука.
У нас раньше использовалась старая опция, и были жалобы от пользователей, что их не устраивает качество проигрываемого и записываемого звука внутри приложения. Мы поменяли опцию, все стало лучше.
Если вы хотите использовать одновременно и распознавание, и синтез речи, используйте категорию playAndRecord. Тогда в рамках активированной аудиосессии можно использовать и запись, и проигрывание звука.
Отдельно стоит рассмотреть опцию notifyOthersOnDeactivation. Используется она в методе активации аудиосессии. Почему она так важна?
Если аудиосессия была деактивирована с этой опцией, то другие приложения получат идентификацию AVAudioSessionInterruptionNotification с параметром AVAudioSessionInterruptionTypeEnded с параметром, что прерывание их аудиосессии закончилось и они могут продолжить работу со звуком, начатую до того, как они были прерваны.
Такой сценарий возможен, если вы используете категорию playback в приложении без опции mixWithOthers, потому что в противном случае вы не будете прерывать звук другого приложения, ваше аудио просто будет замиксовано с другим приложением.
Использование этой опции и правильная обработка модификации позволяет предоставить пользователям комфортный user experience при работе с вашим приложением.
На слайде можно увидеть пример, как правильно обрабатывать нотификацию о том, что ваше приложение было прервано другим в рамках аудиосессии, и ситуацию, когда прерывание закончилось. То есть мы подписываемся на определенную нотификацию и, может быть, два типа: когда прерывание только началось и когда оно закончилось.
В первом случае вы можете сохранить состояние, а во втором можете продолжить проигрывание звука, который был прерван другим приложением.
Вот пример, как это может работать:
Видео будет проигрываться с того момента, где демонстрируется пример
В этом примере музыка проигрывалась в другом приложении, а именно в VLC, затем я запустил озвучку внутри нашего приложения. Музыка прервалась, произошло проигрывание синтезированной речи, затем музыка автоматически продолжила проигрываться.
Хочу отметить, что не все приложения правильно обрабатывают ситуацию, когда их звук прерывается. Например, некоторые популярные мессенджеры не возобновляют проигрывание звука.
Подытожим. Мы разобрали принцип работы аудиосессии. Рассмотрели возможности конфигурации аудиосессии под требования ваших приложений и научились комфортно для пользователя активировать и деактивировать аудиосессию.
Идем дальше. Синтез речи.
На слайде условно представлена диаграмма задействованных классов в процессе синтеза речи. Основными классами являются AVSpeechSynthesiser, AVSpeechUtterance и AVSpeechSynthesisVoice с его настройками.
Отдельно отмечу, что есть AVSpeechSynthesizerDelegate, который позволяет вам получать уведомления о жизненном цикле всего запроса. Поскольку озвучивание текста — это проигрывание звука, неявной зависимостью здесь будет рассмотренная ранее AVAudioSession.
Можно сделать запрос на распознавание и без настройки аудиосессии, но для любых продакшен-приложений важно понимать, как ее настраивать. Мы говорили об этом ранее.
Самый коротенький пример того, как можно быстро сделать запрос на синтез речи. Вам нужно создать объект класса AVSpeechUtterance, где вы указываете текст, который хотите озвучить, желаемый голос и язык. Если вы не укажете локаль языка при создании голоса, то будет использоваться локаль вашего телефона по умолчанию. Но о выборе голосов и о том, как с ними работать, мы поговорим в следующих слайдах.
Далее вы создаете объект класса AVSpeechSynthesizer и вызываете метод speak. Всё. После этого текст будет синтезирован и проигран, вы услышите результат.
Но на самом деле, это только начало. У синтеза речи намного больше возможностей, о которых мы сейчас и поговорим.
Первое — можно задать скорость при приеме звука. Скорость задается в виде вещественного числа в диапазоне от нуля до единицы. Фактическая скорость изменяется в значении от нуля до единицы, если вы устанавливаете свойство rate в диапазоне от 0 до 0,5.
Если же вы устанавливаете значение rate в диапазоне от 0,5 до 1, то скорость меняется пропорционально в значениях от 1X до 4X.
Пример того, как можно работать со скоростью.
В AVFoundation существует константа AVSpeechUtteranceDefault, которая на самом деле равняется 0,5, что эквивалентно обычной скорости проигрывания звука.
Также вы можете указать скорость вдвое меньше обычной, вам нужно указать значение 0,25. Если вы укажете 0,75, скорость будет увеличена в 2,5 раза от нормальной. Также для удобства есть константы на минимальную скорость и на максимальную.
Сейчас я проиграю несколько примеров:
Видео будет проигрываться с того момента, где демонстрируется пример
Это был пример того, как Макинтош в первый раз заговорил собственным голосом на одной из презентаций Apple. И это был пример нормальной скорости синтезированной речи.
Это — замедленная в 2 раза.
Это — ускоренная в 2,5 раза.
Отдельно последними строчками я вывел свойства preUtteranceDelay и postUtteranceDelay. Это задержка перед тем, как звук начнет проигрываться, и задержка после того, как он закончил проигрываться. Удобно использовать, когда вы миксуете свое приложение со звуком из других приложений и хотите, чтобы громкость понизилась, прошло какое-то время и вы проиграли свой результат. Потом подождали еще какое-то время, и только после этого громкость в другом приложении вернулась на исходную позицию.
Посмотрим следующий параметр — выбор голоса. Голоса для синтеза речи голоса делятся в основном по локали, языку и качеству. AVFoundation предлагает несколько способов создать или получить объект AVSpeechSynthesisVoice. Первый — по идентификатору голоса. У каждого голоса есть свой уникальный ID, и список всех доступных голосов можно узнать, обратившись к статическому свойству SpeechVoice. Получение этого свойства имеет некоторые особенности, мы поговорим о них далее.
Стоит отметить, что если вы передадите не валидный идентификатор в конструктор, то конструктор вернет «нет».
Второй вариант — получить по коду языка или локали. Также хочу отметить, что Apple говорит, что голоса Siri недоступны, но это не совсем правда: нам удалось получить идентификаторы некоторых голосов, которые используются в Siri на некоторых устройствах. Возможно, это баг.
У голосов бывает два качества — дефолтное и улучшенное. Для некоторых голосов можно скачать улучшенную версию, мы поговорим об этом в последнем разделе, обсудим, как можно докачать необходимые голоса.
Пример того, как можно выбрать конкретный голос. Первый способ — по конкретному идентификатору, второй — по строке, обозначающей код языка, третий — по конкретной локали.
Хочу вам сейчас проиграть два примера озвучивания одного и того же текста разными локалями.
Видео будет проигрываться с того момента, где демонстрируется пример
Второй вариант, мне кажется, ближе к российскому произношению.
Также в iOS 13 появился Gender. И это свойство доступно только на iOS 13 и больше, оно работает только для голосов, которые были добавлены в iOS 13. Поэтому Gender задается в виде enum и имеет три свойства: Female, Male и Unspecified.
В нашем приложении можно выбрать пол голоса, которым будет озвучиваться текст. Для старых голосов мы сами составили список и храним его у нас в приложении. Разделение того, какой голос мы считаем мужским, какой женским, для тех голосов, для которых система возвращает Unspecified.
В iOS 13.1 список голосов может вернуть пустой список при первом обращении. Решение: вы можете перезапрашивать раз в какое-то количество секунд весь этот список. Как только он возвращается не пустой, считаем, что мы наконец-то получили актуальный список голосов.
В последующих версиях iOS этот баг был исправлен, но не удивляйтесь, если встретите такое в своих приложениях.
Интересный момент, на который я натолкнулся, когда исследовал документацию: существует статическое свойство AVSpeechSynthesisVoiceAlexIdentifier. Это очень интересный идентификатор, потому что, во-первых, далеко не на всех устройствах можно с этим идентификатором создать голос. Во-вторых, мне непонятно, почему он находится отдельно. В-третьих, если же все-таки получить голос с этим идентификатором, то этот голос имеет уникальный и отличный от других класс.
При этом исследование хедеров фреймворков ничего полезного и интересного мне недало. Если вы знаете какую-то информацию про этот идентификатор — зачем он нужен, почему появился, — расскажите мне, пожалуйста. Я так и не смог найти ответ на этот вопрос.
Здесь можно наблюдать пример того, как мы сделали в интерфейсе выбор голоса на основе локали, пола и как мы даем возможность указывать скорость озвучки для конкретного языка.
Коротко расскажу про систему знаков для записи транскрипции на основе латинского языка. Когда вы отдаете текст на озвучку, то можете указать произношение конкретных слов внутри него. В iOS это делается через NSAttributedString, с указанием специального ключа. Генерация этого произношения доступна прямо на iOS-устройстве в разделе Accessibility. Но для больших объемов, мне кажется, это очень неудобно, и можно автоматизировать генерацию фонетической транскрипции другими способами.
Например, вот репозиторий, в котором для английского языка есть большой словарь соотношения слова и его произношения.
На слайде — пример того, как можно для одной локали заменить произношение конкретного слова. В данном случае это |təˈmɑːtəʊ|, tomato.
Видео будет проигрываться с того момента, где демонстрируется пример
Сейчас был проигран вариант с установкой атрибута на произношение и без.
Итого мы рассмотрели способы создания запроса на синтез речи. Научились работать с голосами. Рассмотрели обход одного из багов, который вам может встретиться, и посмотрели на фонетическую транскрипцию, как ее можно использовать.
Плавно переходим к распознаванию речи. Оно в iOS представлено в виде фреймворка под названием Speech, и оно позволяет осуществлять распознавание речи прямо на ваших устройствах.
Поддерживается приблизительно 50 языков и диалектов, доступно начиная с iOS 10. Обычно распознавание речи требует подключения к интернету. Но для некоторых устройств и для некоторых языков распознавание может работать в офлайн-режиме. Мы поговорим об этом в четвертой части моего доклада.
Распознавание речи доступно как с микрофона, так и из аудиофайла. Если вы хотите предоставить пользователю возможность распознавать речь с микрофона, то пользователь должен дать разрешение на два permissions. Первое — на доступ к микрофону, второе — на то, что его речь будет передана на сервера Apple для проведения распознавания.
К сожалению, нельзя там, где вы можете использовать только офлайн-распознавание, не запрашивать этот permission. Его нужно запросить в любом случае.
Список взят с сайта Apple. Это те языки и локали, которые доступны для распознавания речи. Но на самом деле это список языков и локалей, доступных для диктовки на стандартной клавиатуре. И API фреймворка Speech под капотом ссылается на реализацию диктовки из стандартной клавиатуры.
Распознавание речи бесплатно для нас как для разработчиков, но оно имеет лимит на использование. Первое — лимит по устройствам и запросам в день. Второе — общий лимит для приложения. И третье — распознать можно максимум одну минуту. Исключение составляет офлайн-режим. В нем вы можете делать распознавание длинных записанных аудиосообщений.
Apple, конечно, не говорит конкретные цифры по лимитам, и как было написано или было сказано на докладе WWDC, нужно быть готовым к обработке ошибок писать им, если вы часто, скажем так, утыкаетесь в эти лимиты. Но у нас такой проблемы нет. Мы для русского языка используем SpeechKit в качестве движка для распознавания речи. А большая часть наших пользователей русскоязычная, поэтому мы так и не столкнулись с лимитами.
Еще обязательно думайте о приватности. Не позволяйте проводить озвучку данных — паролей, данных кредитных карт. Любая sensitive или приватная информация не должна быть доступна для распознавания.
На слайде можно увидеть условную диаграмму задействованных классов в процессе распознавания речи. Аналогично синтезу, работа с распознанием — это работа с аудиожелезом, поэтому здесь тоже явной зависимостью выступает AVAudioSession.
Поддержка. Чтобы получить набор всех поддерживаемых локалей, вам нужно обратиться к страничному свойству supportedLocales. Поддержка определенной локали в целом не гарантирует того, что в данный момент распознавание речи для нее доступно. Например, может требоваться постоянное соединение с серверами Apple.
Поддержка локалей для распознавания соответствует списку локалей для диктовки в клавиатуре на iOS. Вот полный список. Чтобы убедиться, что данная локаль может быть обработана прямо сейчас, вы можете использовать свойство isAvailable.
В распознавании речи на iOS нет приоритета локалей для каждого языка, в отличие от синтеза. Поэтому если из списка всех локалей брать первую локаль конкретного языка, то там может быть какая-нибудь не самая популярная локаль. Поэтому для некоторых языков в Переводчике мы сделали приоритет конкретной локали для конкретного языка.
Например, для английского мы используем en-US. Когда пользователь первый раз пытается что-то распознавать на английском языке, мы используем американскую локаль.
Запрос на распознавание из файла. Здесь все просто. Вам нужно получить и составить ссылку на файл, создать объект SFSpeechRecognizer с указанием локали, которую вы хотите использовать. Проверить, что распознавание доступно в данный момент. Создать SFSpeechURLRecognitionRequest, используя конструкты, в которые вы передаете путь к файлу. И запустить задачу на распознавание.
В итоге вы получите либо ошибку при распознавании, либо результат. У результата есть свойство isFinal, которое обозначает, что этот результат является конечным и его можно использовать далее.
Здесь чуть более сложный пример — запрос на распознавание с микрофона. Чтобы его делать, нам еще нужен объект AVAudioEngine, который отвечает за работу с микрофоном. Не будем вдаваться в детали, как это работает. Вы устанавливаете нужную категорию — либо .record, либо .playRecord. Включаете аудиосессию. Настраиваете AudioEngine и подписываетесь на получение звуковых буферов с микрофона. Вы добавляете их к запросу на распознавание и, когда вы закончили распознавание, можете завершить работу с микрофоном.
Стоит отметить, что свойство shouldReportPartialResults, которое отвечает за выдачу временных результатов распознавания, установлено в true. Давайте посмотрим варианты: как может выглядеть приложение с установленным флагом shouldReportPartialResults и без него.
Видео будет проигрываться с того момента, где демонстрируется пример
В примере слева я оставил реагирование микрофона на звук, на изменение громкости. Там видно, что я что-то говорю. Но пока я не закончу говорить, вы ничего не видите. Проходит достаточно долгое время, пока пользователь получает результат того, что же он надиктовал.
Если же выставить shouldReportPartialResults в true и правильно это обрабатывать, то пользователь будет видеть, что он говорит, по мере своей речи. Это очень удобно и это правильный путь к тому, как нужно делать интерфейс в плане диктовки.
Вот пример того, как мы у себя обрабатываем работу с аудиосессией. Внутри Переводчика мы используем не только работу со звуком, который написали мы, но и другие фреймворки, которые что-то могут делать с аудиосессией.
Мы написали контроллер, который, во-первых, проверяет, что настройки, категории те, которые нам нужны, и во-вторых, не делает того, что постоянно включает и выключает аудиосессию.
Еще до разработки диалогового режима ввод голосом и озвучка у нас сами включали и выключали аудиосессию. Когда мы начали делать диалоговый режим, получилось, что эти включения-выключения добавляют лишнюю задержку между тем, как ты что-то произнес, и получением озвучки.
У запроса на распознавание речи можно указать подсказку — тип распознаваемой речи. Это может быть unspecified, может быть диктовка, поиск или короткое подтверждение. Чаще всего, если ваш пользователь будет говорить что-то длинное, лучше использовать dictation.
Начиная с iOS 13 нам доступна аналитика аудио. На слайде представлены те параметры, которые можно получить в результате распознанной речи. То есть вам в качестве результата придет не только то, что пользователь сказал, но и то, каким голосом он это говорил.
Не будем на этом долго останавливаться. Вот пример того, как можно получить аналитику в результате распознанного текста.
Итого мы изучили возможности фреймворка Speech для распознавания речи, научились давать подсказки для распознавания речи и быстро посмотрели на возможности аналитики.
И последнее по списку, но не по важности: работа в офлайн-режиме. Первое, о чем хочется рассказать, — это список офлайн-языков для синтеза речи. Нигде в документации я не нашел упоминания того, как можно явно скачать голоса для работы в офлайне. Что на докладах, что в документации говорится о том, что эти голоса могут быть докачены, но где — не написано.
Я поискал по системе и нашел, что если зайти в Настройки, в раздел Accessibility, далее «Устный контент» и «Голоса», то вы увидите, во-первых, список языков, для которых это доступно. Во-вторых, перейдя в конкретный язык, можно докачать новые голоса.
И этот список четко совпадает с тем, что возвращает AVSpeechSynthesisVoice.speechVoices внутри приложения. Это означает, что вы можете научить ваших пользователей, что они могут докачать нужные языки, чтобы пользоваться синтезом речи в офлайне.
Список офлайн-языков для распознавания. Нигде в документации он явно не указан, но судя по разным форумам и по тому, с чем мы сталкивались, так выглядит список языков и локалей для них, которые могут работать в офлайне без доступа в интернет.
Стоит отметить, что распознавание в офлайне доступно на устройствах с чипом A9 и старше.
Теперь самое интересное. Список офлайн-языков для распознавания речи. В отличие от синтеза, здесь вообще нет возможности явно скачать себе языки. Если добавить язык в стандартную клавиатуру, для него может быть скачать офлайн-пакет. Но к сожалению, это не детерминировано. Перейдем в Настройки > Основные > Клавиатура > Диктовка. Я, например, добавлял испанский. После этого под «Диктовкой» появляется маленькая подсказка, что диктовка может быть доступна вот для этих языков. Там появился испанский.
Затем я перешел в наше приложение, отключил интернет, и к моей радости в офлайн-режиме распознавание на испанском работало.
К сожалению, на это можно повлиять только косвенно, единственный способ — добавить язык в стандартную клавиатуру. Но это не гарантирует того, что офлайн-пакет для распознавания будет скачан.
В iOS, даже если у вас есть доступ к интернету на телефоне, вы можете зафорсить устройство и делать распознавание речи на нем, если распознавание, конечно же, доступно.
Есть свойство supportsOnDeviceRecognition, оно доступно начиная с iOS 13. Но это свойство работает некорректно, я справа внизу показал скриншот ошибки. Ошибка была исправлена только в 13.2. Свойство всегда возвращает false при первом запросе. Согласно Apple, оно вернет корректное значение спустя несколько секунд.
Причем это свойство может отдавать false, но в то же время установка флага requiresOnDeviceRecognition в true работает успешно. Значит, распознавание полностью работает на устройстве, даже если этот проверочный флаг возвращает false.
Здесь может быть несколько решений. Во-первых, вы можете делать офлайн-распознавание только на iOS 13.2. Во-вторых, можете подобрать какое-то количество секунд для перезапроса этого свойства и обновлять интерфейс для пользователя. И в-третьих, вы можете забить на это свойство: пробовать распознавать голос в офлайне, а в случае ошибки просто показывать ее пользователю.
Мы посмотрели, как можно явным образом скачать пакеты для синтеза речи в офлайне, и нашли способ попробовать заставить iOS скачать офлайн-пакеты для распознавания.
Теперь вы знаете, как быстро добавить в ваши приложения синтез и распознавание речи. У меня всё, спасибо за внимание.




Добавить комментарий